
はじめに
SELECT文は、データベースのデータを検索し取得するためのSQLです。
検索する命令なので、様々な条件を付けていくことが可能です。
基本の使い方から、検索条件の付け方まで学んでいきましょう
Step1: 概念を知る
SELECT文
テーブルから情報を検索し取得する際に用います。
テーブル名、取得するカラム名を指定することで、テーブルに登録されているデータから指定したカラムの情報を取得します。
Step2: 使い方を知る
基本
CREATE文のところで作成したpersonテーブルをもとに説明します。
personテーブルには、
・person_id
・fname
・Iname
・gender
・birth_date
のカラムがあります。
この中で、名前の項目のみ一覧で取得したい場合は、fnameとInameのカラムを指定します
1.SELECTを宣言し、取得したいカラム名を記述します。
2. テーブルの名前を指定し、どのテーブルから情報を取得するのかを決めます。
全てのカラムの情報が欲しい場合、もちろんカラム名を網羅して書くことでも取得できますが面倒くさいですよね。
そこで、便利な記号として*があります。
一般にワイルドカードと呼ばれ、全てという意味があります。
カラム名の代わりにこの記号を記述することで、テーブル内すべての要素を取得することができます。
応用
皆さんがGoogleで検索をするとき、様々なキーワードを入力することで知りたい情報を絞りますよね。
データベースでも同様に、知りたい情報を絞るためのSQLがあります。
それがWHERE句と呼ばれるものです。
WHERE句では様々な条件で取得する情報を絞り込むことができますが、主に使用されるのが、指定したカラムの値による絞り込みです。
一致検索
先ほどのpersonテーブルで考えてみます。
personテーブルの中に格納されたデータから、名字が「渡辺」さんのデータが欲しいとしましょう。
1. テーブル名の後ろにWHEREと追記します。
2. WHEREの後ろにカラム名=検索したい値の形で検索条件を記述します。
名字が渡辺のデータが欲しい場合はfname=’渡辺’ですね
また、検索条件を複数設定することもできます。
先ほどの名字が「渡辺」さんであるデータの中で名前が「太郎」であるデータが欲しいとします。
複数の検索条件はANDでつなぐことで指定できます。
部分一致検索
ここからは部分一致検索について説明します。
部分一致検索とは、検索に使用する値が「含まれた」データを取得する検索の仕方です。
一致検索では=でカラム名と検索したい値を結んでいました。
部分一致では=の代わりにLIKEを使用します。
- WHEREの後ろにカラム名 LIKE 値と入力します。
ここで一つ注意があります。
部分一致検索には、前方一致、後方一致、中間一致の3種類があります。
前方一致:対象文章の部分の前(1文字)目からが一致すること
後方一致:対象文章の部分の末尾が一致すること
中間一致:対象文章の一文字目と末尾を含まず一致すること
この3種類のどれで検索をするのかも指定する必要があります。
PostgreSQLでの前方一致、後方一致、中間一致の検索は、LIKE演算子とワイルドカード文字 % を使用して実現できます。
前方一致: LIKE '検索文字列%'
後方一致: LIKE '%検索文字列'
中間一致: LIKE '%検索文字列%'
% は、0文字以上の任意の文字列を表します。
テーブル結合
テーブル操作の山場の一つ、テーブル結合についてです。
別々のテーブルを、条件をもとに一つのテーブルにまとめてから検索をすることができます。
何言ってるかわからん!となった方、安心してください。順を追って説明します。
まず、そもそもテーブル結合のイメージからとらえていきましょう。
先ほどのpersonテーブルのほかに、もう一つ社員テーブルがあるとしましょう。
社員テーブルでは、
・fname(社員の名字)
・lname(社員の名前)
・age(社員の年齢)
・department(所属部署)
・post(役職)
が定義されています。
ある会社の部署で、その月が誕生月の所属社員を祝う習慣があったとします。今月は誰が該当するのかな?をDBを利用して絞り込みます。
personテーブルでは誕生日を取得できるので誰がその月に誕生日があるのかがわかります。社員テーブルではだれがその部署に所属しているのかが取得できます。
これらを別々に取得するのではなく、同時に取得出来たら便利ですよね。
ここで活躍するのがテーブル結合です!
二つのテーブルの共通するカラムで検索を行い、二つのテーブルのカラムをくっつけて同時に取得することができます。
今回のpersonテーブルと社員テーブルでは、社員の名前(fname、lname)が共通になっています。
そこで、WHERE条件にperson.fname=社員.fname、person.lname=社員.lnameと記述することでテーブルを共通カラムで結合します。
これにより取得をすると、下図のようになります。
データベースではテーブルに登録するカラムは必要最低限の情報であることが求められます。(カラムが多すぎると、テーブルがなんの情報を持っているのかわかりにくく、検索をする際も時間がかかってしまうことがあります。)
このテーブル結合を使いこなすことで、複雑なデータ取得条件に対応することができます。
テーブル結合には大きく二つの種類があります。
「内部結合」と「外部結合」です。
先ほど説明した結合は内部結合であり、外部結合ではまた少し書き方や使い方が異なります。
詳しくは自身で調べてもらうとして、簡単な違いは以下になります
・内部結合は、結合条件(共通のカラム)に指定した項目の値が、両方のテーブルに存在するときのみ、お互いのレコード(情報)を抽出して結合します
・外部結合は、基準となるテーブルを設定し、その基準テーブルに存在するレコードを抽出。基準でないテーブルからは、結合条件に合致するレコードのみを抽出して結合します。(personテーブルが基準なら、personの情報はすべて取得でき、社員テーブルからはpersonテーブルに存在する名字と名前に合致するものだけとってくるので、社員テーブルの情報がからになって結合されている場合があります。)
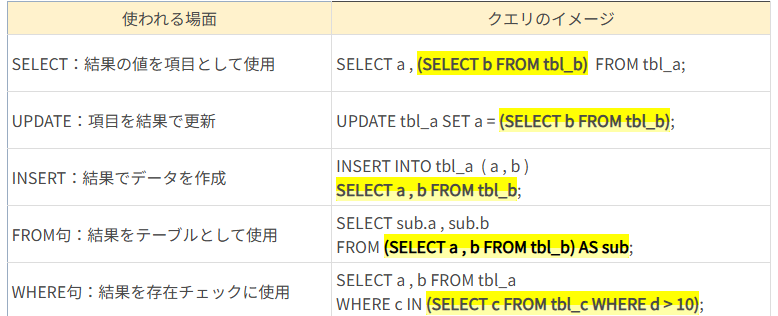
副問い合わせ(サブクエリ)
サブクエリとは、ズバリ言うと「SQLの中でSQLを呼びだす」ことです。
SELECTの章で紹介していますが、のちに紹介するINSERT文やUPDATE文でも利用することができます。
サブクエリのメリットとして、複数のSELECT文を1つにまとめて記述できたり、複雑なテーブル結合を使わずに記述できたりという点があります。一方、デメリットとして、処理速度が遅くなる場合がありますので、使用には注意が必要です。
クエリの結合
先ほど説明したテーブル結合とは少し違う結合の仕方、それがクエリの結合です。ここでは簡単に説明していきます。
まず、クエリの結合には3種類あり、
・和(UNION)
・差(INTERSECT)
・積(EXCEPT)
があります。今回はUNIONをもとに説明します。
先ほどのテーブル結合では
「検索対象のテーブルを結合→検索条件に合わせて抽出」
という順番で実行されるのに対し、クエリ結合では
「複数のクエリを実行→抽出された結果を結合」
という順番で実施されます
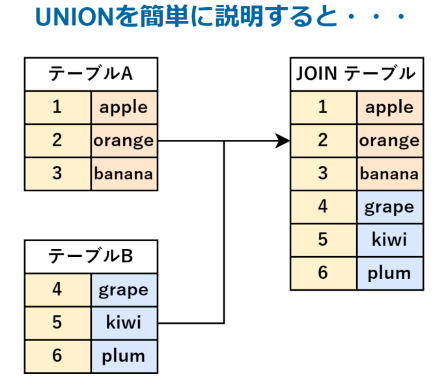
二つの検索結果で重複する部分は自動的に削除されます(UNION ALLと記述すると重複する行も含めて結合されます)
テーブル結合では横に結合するイメージ、UNIONでは縦に結合するイメージでとらえてもらうと少しわかりやすくなると思います。
また、テーブル結合と同様に、結合するカラムがそろっていないとUNIONを使用できないため注意してください。
さいごに
ここで説明した内容は基本的かつかなり簡素に伝えています。詳しい利用の仕方や利用場面については各自でしっかりと調べましょう(かなり奥が深いので、時間をかけて研鑽していきましょう!!)